Stable Video Portraits
Mirela Ostrek and Justus Thies
European Conference on Computer Vision (ECCV) 2024, Milano, Italy
{kind=link}

Abstract
Rapid advances in the field of generative AI and text-to-image methods in particular have transformed the way we interact with and perceive computer-generated imagery today. In parallel, much progress has been made in 3D face reconstruction, using 3D Morphable Models (3DMM). In this paper, we present Stable Video Portraits, a novel hybrid 2D/3D generation method that outputs photorealistic videos of talking faces leveraging a large pre-trained text-to-image prior (2D), controlled via a 3DMM (3D). Specifically, we introduce a person-specific fine-tuning of a general 2D stable diffusion model which we lift to a video model by providing temporal 3DMM sequences as conditioning and by introducing a temporal denoising procedure. As an output, this model generates temporally smooth imagery of a person with 3DMM-based controls, i.e., a person-specific avatar. The facial appearance of this person-specific avatar can be edited and morphed to text-defined celebrities, without any test-time fine-tuning. The method is analyzed quantitatively and qualitatively, and we show that our method outperforms state-of-the-art monocular head avatar methods.
Method
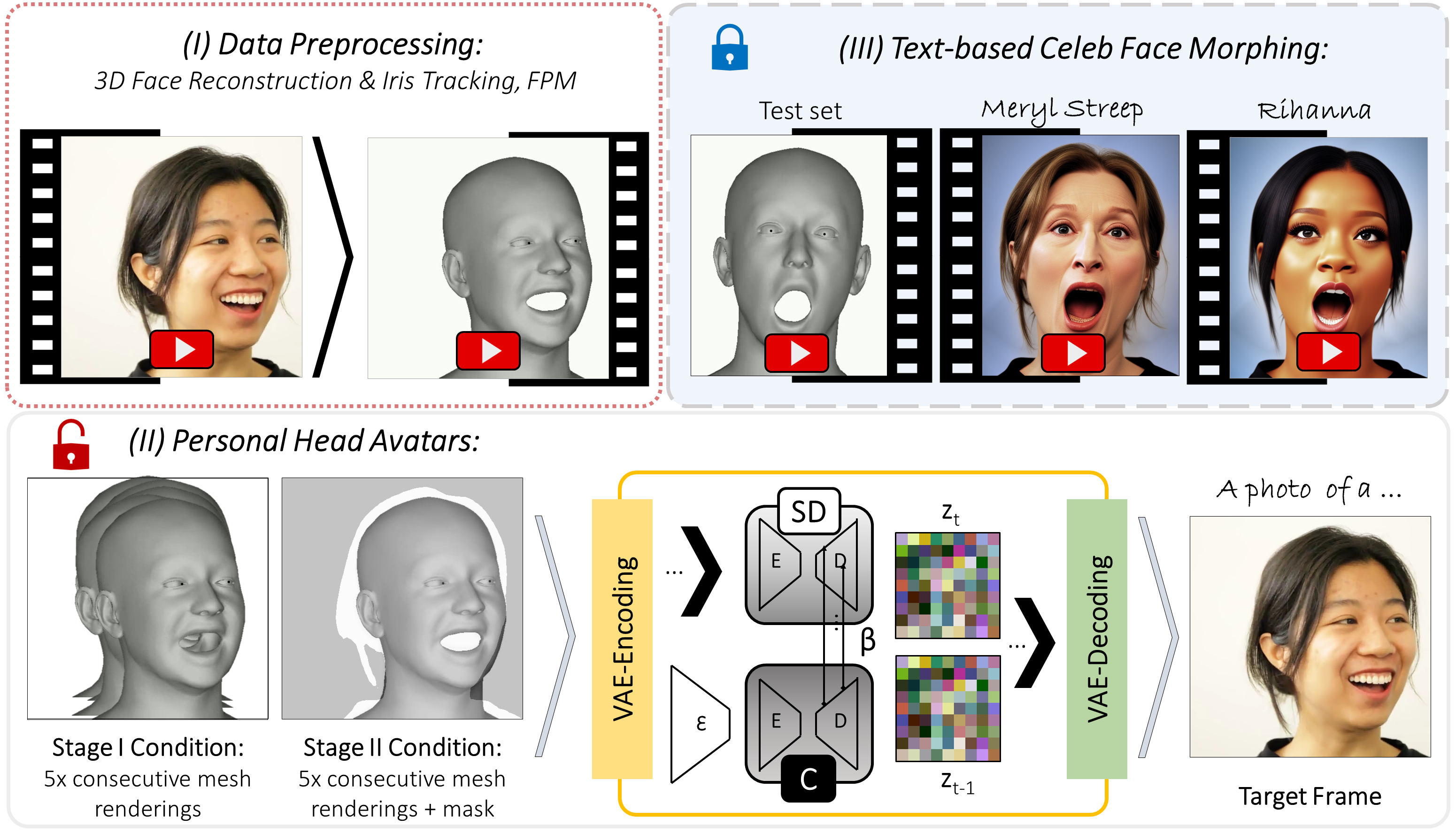
System Overview: (I) Using an off-the-shelf 3D face reconstruction method, face parsing maps (FPM) model, and Mediapipe, the input video is processed to extract per-frame 3D face reconstructions (3DMM), FPM, and the iris location. (II) Based on this data, two ControlNets are trained in parallel, allowing for the generation of temporally stable outlines (Stage I) and inner details (Stage II), resulting in photo-realistic personal avatars (SD is fine-tuned in the unlocked mode). (III) Person-specific avatars may be further morphed into a celebrity via text, without additional fine-tuning (using the locked SD).
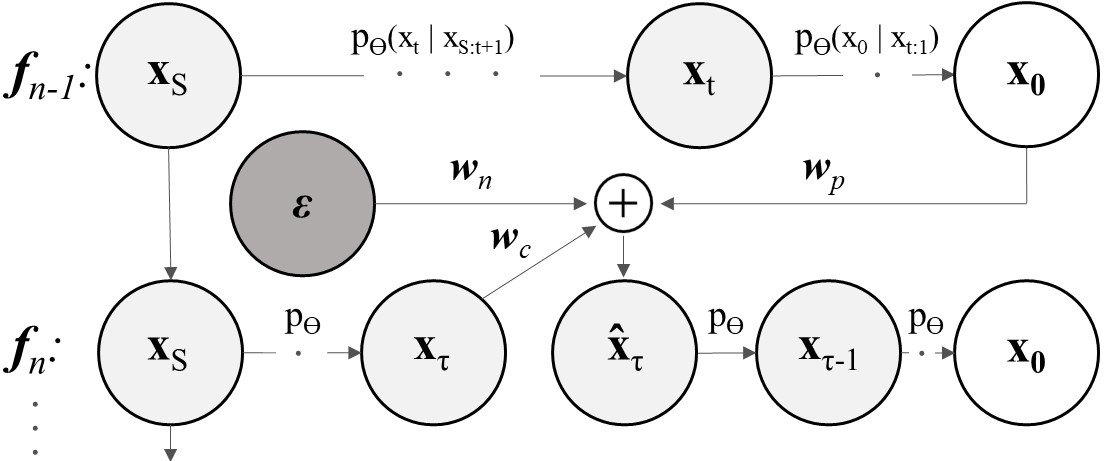
Spatio-temporal Denoising: Using the prediction for the frame fn-1, we modify the inference in the DDIM step t=τ for frame fn to consider the previous frame, which leads to temporally smooth outputs, controlled by wc, wp, and wn.
RESULTS
Face Morphing ID-1:
Face Morphing ID-1, as Scarlet Johansson (Head Pose Consistency):
Face Morphing ID-2:
Face Morphing ID-2, as Emma Watson (Head Pose Consistency):
Face Morphing ID-3, Expression Consistency:
Face Morphing ID-4, Camera-View Consistency:
Comparison with SOTA Monocular Head Avatar Methods:
ABLATION STUDIES
Morphing Factor:
Input Controls:
Denoising Process Variables:
Citing the Stable Video Portraits Paper and Dataset
If you find our paper or dataset useful to your research, please cite our work:
@inproceedings{SVP:ECCV:24, title = {Stable Video Portraits}, author = {Ostrek, Mirela and Thies, Justus}, booktitle = {European Conference on Computer Vision (ECCV)}, month = October, year = {2024}, month_numeric = {10}}